(2026.2.4.)
IRT, 특히 오지선다와 같은 multiple-choice items에 관한 방법론인 nominal response model (NRM)을 물리학적으로 풀어낸 논문이다. 2022년 논문인데 7회밖에 인용되지 않은 점이 조금 아쉽지만, 내 연구 문제의식과 가장 가까워 보여서 preliminary study 삼으면 좋을 것 같았다.
Introduction에서 저자들은 IRT에 대해 간단히 설명한다. 2PL model은 IRT의 대표적인 모델 중 하나인데, 문제 의 변별도 와 난이도 에 대해 다음과 같은 수식으로 표현된다.
이 식은 약간의 변형과 의 도입(재매개변수화)을 통해 다음과 같이 바꿀 수 있다.
이 식은 정답이 옳고 그름만을 표현한 식이기 때문에, 여러 선택지가 있는 객관식 문제는 다음과 같이 식을 세울 수 있다.
이 식, 즉 IRT nominal response model (NRM) 을 처음 제안한 것이 Bock (1972) 논문이다. (나는 혼자 이걸 만들어두고 최초일 거라고 생각했다…)
이 NRM은 여러 기능이 있다.
- 똑같이 틀렸더라도 무엇을 틀렸느냐에 따라 다른 로 추론할 수 있다.
선지의 순서를 결정할 때 사용할 수 있다.- Transition matrix나 consistency plot을 이용해서 수업 전후로 어떤 응답 변화가 일어났는지 점수 배정 없이 알 수 있다.
- 는 높을수록 높은 값에서의 변별과 상관성이 크다. /이를 통해
이 논문에서는 위의 NRM에 대한 수학적, 물리적 framework를 제시한다.
“In this paper, we provide new insights into why the ordering of the values from the NRM may be used as a proxy for ordering the ‘correctness’ of each response option.”
즉, 각 선택지 가 가지는 계수 의 순서가 곧 그 선택지의 정답성(correctness)을 나타낸다는 것이다.
한 학생이 문항 에 대해 응답 를 선택했을 때, 이 학생의 잠재(latent)적인 능력치 는 이며, 베이즈 정리를 이용해 다음과 같이 다시 쓸 수 있다.
이때 는 이전에 NRM에서 논하지 않았는가? 이를 대입하면 다음과 같다.
우변에서 는 알지 못하지만, -dependent하지 않으므로 개형에는 영향을 주지 못한다(이러한 접근은 통계물리에서 흔한 접근이다). 또한, 능력치의 분포 는 정규분포를 따른다는 것이 일반적인 가정이다(IRT의 ‘가정’ 설명 참고).
이러한 가정 하에서 큰 데이터셋에서 집합을 찾아보겠다. 사용할 데이터는 당연히 multiple-choice 문항반응 데이터여야 한다. 이 연구에서 사용한 데이터셋은 다음과 같다.
- FMCE
- PhysPort DataExplorer database
- Learning About STEM Student Outcomes (LASSO)
- MIRT package in the R computing environment
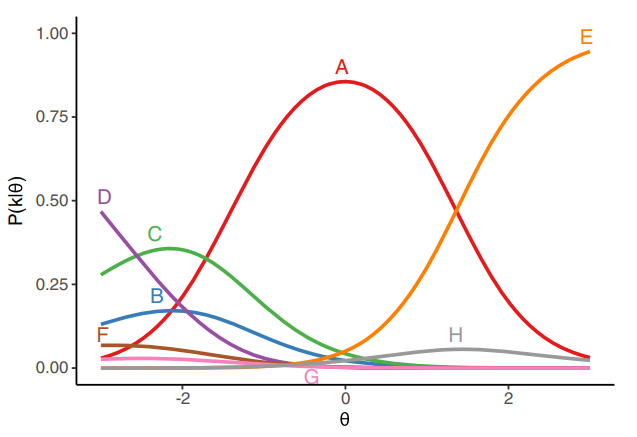
위는 FMCE의 14번째 문제에 대한 IRF fitting 결과(category characteristic curves)로, x축(능력치)에 대한 해당 선택지를 고를 확률을 y축으로 나타낸 것이다. 아마 당연히 각 에 대해서 A-H를 모두 더하면 1.00이 될 것이다.
(메모) 내 논문 주제는 E의 개형이 뒤틀리는 것!